

Volume: 9, Issue: 1
15/05/2017
15/05/2017
KEYWORDS: corpus linguistics, pre-service ESL teachers, pedagogy
ABSTRACT: Scholars who research corpora and its pedagogical implications differ in their views; some believe that corpora should be integrated into teaching practices and teacher training programs, while others caution against such implementations and suggest that critical examinations of corpora use in classroom needs to be in place. To better understand the pedagogical implication of corpora, this study uses surveys and interviews to explore ten pre-service ESL teachers’ perception of using Corpus of Contemporary American English (COCA) in ESL classrooms. The result suggests that COCA is beneficial for ESL teachers in designing classroom materials and developing digital literacy; however, our finding also indicates that learners’ L2 proficiency and logistics need to be taken into consideration when using COCA in classrooms.
With the emergence of new technologies such as emails, chat rooms, and World Wide Web and the turn for plurality and fluidity in language learning, both scholars and educators have realized the potential value of information communication technology (ICT) to develop language teachers’ multiliteracies competence, the ability to communicate with others via digital and online mediums (Cummins, 2000; Warschauer, 2000). Teaching with technology is likely to create an emancipatory learning environment in which individuals could use technology to obtain their authorship in the process of disseminating knowledge based on their own understandings and views (Lotherington & Jenson, 2011). Thus, scholars such as O'Keeffe and Farr (2003) note that technology needs to become integrated into teacher education programs so that future teachers can see the benefits of using technology tools in teaching and understand the importance of developing multiliteracies. In the current study, we thematically analyzed preservice ESL teachers’ perception of using COCA in classrooms, because we believe that understanding preservice teachers’ view of applying such technology in classrooms would provide more practical feedback to both corpus specialists and the English language teaching (ELT) profession. In the following sections, we will first review the concept of corpora, current debate regarding both sides of using corpora in ELT. Then, we will introduce the research context and participants and how the study was conceived and operationalized. Detailed analysis of our findings along with pedagogical implications will be discussed.
Definition of Corpora
As a pioneering corpora researcher, McKay published the first empirical study investigating teaching strategies of verbs using computer corpus in 1980. Based on his seminal work, various volumes and papers have devoted to conceiving Corpus Linguistics as a field and exploring its applicability to language teachers and learners (Boulton & Pérez-Paredes, 2014; Gries, 2009; Kennedy, 2014; McEnery, Xiao, & Tono, 2006;). As commonly defined, a corpus is a linguistic database that consists of “a collection of naturally occurring language text, chosen to characterize a state or variety of a language” (Sinclair, 1991, p. 171). Over the years, corpus specialists have created multimillion size corpora to facilitate language research and ELT, including but not limited to Corpus of Contemporary American English (COCA, 450 million), British National Corpus (BNC, 100 million), and Michigan Corpus of Academic Spoken English (MICASE, 1.8 million). Two views regarding ELT using corpora have developed, and it is the discussions of these views to which we turn now.
For Corpora Use
From a teaching perspective, data from a computer corpus provides more useful information than dictionaries through concordance lines because teachers could use a corpus to examine the nuances between synonyms such as “big” versus “large” in different contexts (Tsui, 2005, p. 340); additionally, using corpus data helps teachers understand that language is usage-based and that prescriptive grammars could at times be inaccurate in explaining how language is used in daily communications (Tsui, 2005). Tsui’s findings align with other studies that explored the effectiveness of using corpora to teach English grammar and vocabulary through learners’ noticing of certain lexicogrammatical patterns embedded in concordance texts (Liu & Jiang, 2009) and the inductive and deductive learning opportunities created by using corpora in learning English language (Hunston, 2002; Sinclair, 2004). For instance, Liu and Jiang (2009) have observed that some benefits of using corpora in teaching include promoting learners’ awareness and discovery learning ability, enhancing learners’ understanding of lexicogrammatical rules and patterns, and developing an awareness of context. Similarly, Kaltenbock and Mehlmauer-Larcher (2005) indicate that computer corpora are of significant assistance in learning collocations and could help learners better understand semantic prosody of certain lexical items.
Against Corpora Use
Despite the preceding discussions of the benefits of using corpora in ELT, a few scholars have questioned its pedagogical application and believe that corpora represent externalized language data that has limited influence on language learners. For example, Prodromou (1997) argues that there needs to be more corpora to reflect the diversity of English language so that nonnative English speaking teachers could also be legitimately included in the TESOL profession. Widdowson (2000) claims that one acts as a third person observer in viewing the concordances in a corpus, which prevents one from having a direct experience with those concordance lines. Although research suggests that teachers are the ones who play a more crucial role on popularizing language teaching with corpora than corpora itself (Mukherjee, 2004). The above description centers on the discussion of corpora as not relatable to language learners and how language teachers may contribute to the appropriation of corpora for their own classrooms. Thus, the current study aims at understanding the pedagogical aspect of corpora use in ELT through examining ten U.S. pre-service ESL teachers’ perception of using COCA in classrooms.
Methodology
Context and Participants
Situated from a thematic analysis framework, the current study seeks to explore ten pre-service ESL teachers’ perceptions of using COCA in ESL classrooms. The participants are Master’s and PhD students majoring in TESOL, Secondary Education in ESL, and Applied Linguistics. As part of their assistantship package, the master students teach nonnative freshman composition classes. Among these participants, there are eight native English speakers and two non-native English speakers. Four participants had no prior experience with corpora in general and six of them had used COCA a few times. Pseudonyms were assigned to all participants to keep their confidentiality. Researcher Hao Wang is a native speaker of Chinese who is interested in using corpora to enhance ELLs’ language learning experience. Researcher Robert Summers is a teacher educator with rich experience in both foreign language and ESL classrooms at secondary and university level. He is interested in CALL and has conducted research based on Vygotskian framework.
Procedure
The nature of our research question determines that this study will be qualitatively oriented, using common inquiry methods including surveys, interviews, and field notes and In Vivo and thematic analysis as data analysis techniques (Reimer, 1996). The implementation of the multiple data collection methods and researchers’ field notes was conceived to improve the credibility of the study. In addition, we also went back to the participants after completing interview transcription so that further discussions on the research topic or any other relevant matters could be made.
In analyzing the data, In Vivo and thematic analysis are supplementary to each other as they both focus on distilling textual information from the data. In Vivo coding method refers to the process of extracting words and phrases from qualitative data and highlights individuals’ voices in coding (Saldaña, 2012). After initial coding, we conducted a second cycle of analysis by using thematic analysis to synthesize, classify, and conceptualize our previous findings. Thematic analysis is a commonly used data analysis method to encode qualitative information with the facilitation of themes, patterns, and models with themes (Braun & Clarke, 2006).
Before we used our surveys and interviews,, we chose to provide our participants with hands-on experience with using COCA to help them understand and review its features. We conducted a sample lesson on English vocabulary learning with COCA to help familiarize the participants with the COCA website and its basic functions, during which we demonstrated how to use COCA to search for collocates of particular words and pulled up register columns that indicate usage frequency of one word in five registers, namely spoken, fiction, magazine, newspaper, and academic. After our demonstration, the participants were asked to complete a vocabulary worksheet that asks them to find information regarding collocates of a word, how it is used in contexts, and the register where it has been most frequently used. After that we conducted an online survey, designed prior to the sample lesson, to collect the participants’ demographic information and their perceptions of COCA use in classrooms based on our delivery and their hands-on experience. Fifteen themes emerged from the survey responses that were then integrated into our interview questions and used in semi-structured interviews with our participants. After one researcher transcribed the interview recordings, the other one proofread the transcripts. We then used Merriam’s (1988) intensive analysis, developing categories and theory as our guidelines in thematizing our data. First, we read through the transcripts for several times to familiarize ourselves with the texts. This process of familiarization was critical as it enables researchers to discover patterns and topics. In what follows, we used markers to underline sentences and expressions that are relevant to our research topic.
Findings and Discussion
The first two survey questions are demographic in nature. Figures 1 and 2 demonstrate the survey results for the first two questions with ten responding participants.
Figure 1. Participants’ responses to the survey question on their years of teaching
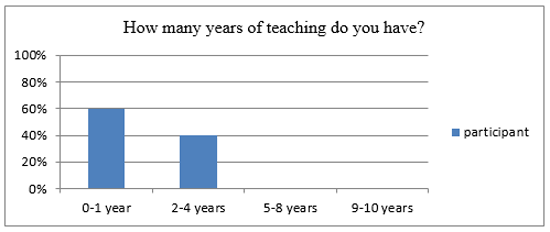
In total, 60% of the participants have had no more than 1 year of teaching experience, and another 40% of the participants’ teaching experience ranged from 2 to 4 years.
Figure 2. Participants’ responses to the survey question on their level of teaching
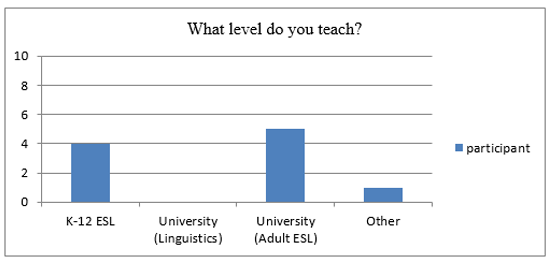
Based on the participants’ teaching level, Figure 2 shows the distribution, four participants were assigned K-12 ESL level, five were assigned university level, and one participant did not have any teaching load.
Thus, most of the participants have had less than four-year teaching experience either in K-12 ESL or University adult ESL settings. Their comments on the remaining five questions were thematized.
Based on the interview results, eight categories were made: student resource, teacher resource, authentic language, access to technology, register, proficiency level, difficult to teach for communicative competence, and too much information. Examples from each category will be given in the following section.
Student resource. One of the features of Corpus Linguistics is its discovery learning, which allows students understand how native English speakers use certain language items thus promoting learner autonomy. In our data, some participants pointed out that students could refer to COCA when they encounter difficulties in English language learning. Additionally, this allows for the development of digital literacy as students learn to answer their own questions through the use of technologically accessible corpora (in this case COCA). Lynn commented that when using COCA to search for unknown words, students are more likely to remember them:
I think when you figure things out for yourself instead of just getting an answer from a teacher you are a whole more likely to remember it and to do it correctly the next time, than just be given the answer every time and you never think about it or remember it.
Teacher resource. Corpus Linguistics has tremendously helped language teachers in designing syllabus, concordance-based materials and activities, tests, and feedback (Braun, 2005). From the comments we received, our participants think that COCA can serve as a teacher resource where they can pull information that will facilitate their lesson preparations; additionally, interactions with COCA are viewed as a rewarding experience for some preservice ESL teachers because they become more professionalized in such processes. In her response, Ashley suggested that in comparison with her native speaker instinct about certain English language usages, COCA is more reliable in answering students’ questions:
Sometimes when students ask me questions I don’t know the answer to, or they ask me what words are common with something, and I’m not sure, then I’ll tell them I’ll bring an answer tomorrow and I use corpus at home to really investigate.
Authentic language. The notion of authenticity is a double-sided sword. If one defines it according to native speaker standard, then it will confront with criticisms from scholars in pluralism and English as Lingua Franca (e.g. Tan, 2005), because such a definition endorses native speakerism that views language via a monolingualism lens and considers native speakers to be superior than nonnative speakers (Holliday, 2006). Thus, whether data from corpora are authentic or not should depend on one’s perspective of authentic language. The responses we garnered reflect authentic language in the sense that how the language is used by native English speakers and within real life contexts. For example, Emma recalled her previous teaching experience with COCA on transitions and suggested that texts from COCA were useful:
Because I wanted to provide the students with authentic examples of how people use these transitions so that they could see the variation and different type, so I pulled some of the common transition words, I pulled examples from COCA for that.
Access to technology. Our literature has indicated that the prominence of Corpus Linguistics is largely due to technological advancement, particularly the availability of computer labs in schools, because language learners would then have hands-on experience with using corpora and develop their abilities in discovering language patterns, comparing differences between registers, and digital technology in general. However, this might not necessarily be the case in practice as our interviewees suggested otherwise. Their main concern is access to technology. Despite the benefits that COCA may bring to ESL students and teachers alike, its demand for technology has caused problems in classrooms, particularly in peripheral countries. Erica, for example, mentioned that although COCA has great advantages in teaching English, many English language learners in China do not have access to technology.
Register. In linguistics, register refers to a variety of a language or level of usage, as determined by degree of formality and choice of vocabulary, pronunciation, and syntax, according to the communicative purpose, social context, and standing of the user (register, n.1.). Some of our interviewees reported that one of their most frequently used functions on COCA is register. As a student teacher, Emma commented that COCA is of great importance to academic writing class mainly because students can distinguish and understand differences:
… between what is slightly formal and appropriate for newspaper, and what is really, what you would use for super formal academic writing, so I think it’s really helpful to be able to compare those types of writing.
Proficiency level. Findings from interviews also indicate that language proficiency level may potentially play a role in students’ COCA use. Jessica, for example, mentioned that advanced learners may use COCA to refine their second language and become more independent in terms of language learning:
I think especially for … high level students … hopefully at that point, they are trying to be a little independent … I think at that level, they would probably be able to work the corpus themselves.
Difficult to teach for communicative competence. The notion of communicative competence was first put forth by Hymes (1971) to describe a person’s ability to use language in a social context. In language learning, this competence is one of a few variables that could influence an individual’s meaningful interaction with others in a foreign language (Savignon, 1972). Based on our interviews, most participants believe COCA does not play a major role in improving learners’ communicative competence. For example, Lynn mentioned that COCA can contribute to students’ awareness of communication in certain contexts but would not significantly improve their L2 communicative competence.
Too much information. The overwhelming number of language data provided by corpora allows learners and teachers to discover language patterns and understand the frequency differences underlying different patterns (Kennedy, 2014). However, in the responses from our participants, this gigantic data size can also pose problems. Some reported that COCA displays concordance lines that are just too overwhelming to students, particularly for students whose L2 proficiency is not well developed and have limited experience using COCA. John commented that the interface on COCA is not very user friendly, especially when the search involves using signs such as brackets and asterisks:
They have a lot of …. symbols and things like that doesn’t make it really user friendly, got be honest, interface is beyond searching for single words or something like that, it gets pretty complex, pretty quickly…
Drawing from the findings of the current research, using COCA in classrooms is a double-sided sword in that its seemingly exploits could be quickly turned into problems for teachers. On the former, our participants suggest that COCA can be a great learning tool for intermediate and advanced language learners who are more capable of understanding the contextual and linguistic information on COCA such as concordance lines. In addition, COCA serves a valuable role in vocabulary learning by providing information such as word frequency, register, and collocations. For example, in explaining the usage differences between say and articulate, the instructor could pull up two charts on the COCA and compare their usages based on the columns of different registers. Another feature of COCA that our participants discussed is its ability to develop learner autonomy and digital literacy. With the multimillion-word COCA, learners who have learned how to navigate COCA linguistically and logistically can use it as an English resource site to explore the language unbounded. Such exploration also develops their digital literacy through interacting with computer technology.
On the other side, using COCA in classrooms is not without limitations. The most important factor to be considered is teachers’ attitudes towards using it. Two of the participants reported that secondary/elementary ESL English teachers rarely use technology in their classrooms. One of the reasons is because of the availability of technology in schools; another important reason is the lack of support from curriculum design. Using supplementary tools such as corpora is not within the school’s current agenda. Second, some instructors consider the massive amount of information on COCA to be problematic, because users need to acquire searching skills such as adding [ ]*, and other symbols when advanced search is in need. The next factor is students’ linguistic and sociocultural knowledge of the language. Without these support, certain lexical items and expressions would be incomprehensible to the students, thus lowering the overall effectiveness of using COCA.
Conclusions, Implications, and Directions for Further Research
Based on the current study, COCA shines in vocabulary instruction, enhancing learners’ awareness of sociolinguistic differences in L2, to some extent improving their communicative competence, and developing digital literacy. However, before implementing COCA, local contexts need to be taken into consideration, which involves teachers’ attitudes towards technology use in classrooms, computer accessibility, and learners’ L2 proficiency and knowledge of COCA. In order to harvest the benefits of COCA or any other corpora, teachers need to first understand that they are the ones who play a critical role in appropriating corpora as a valid teaching tool and developing students’ knowledge in using them. To that end, COCA needs to be integrated into pre-service teacher training programs so that student teachers could increase their familiarity with COCA and know how to effectively use it in classrooms. Additionally, teachers need to carefully select appropriate content from COCA so that students would not be overwhelmed by too many new words and expressions. It should also be noted that the participants in the current study comprised of eight Master students and two PhD students. Future research in this direction could further diversify the demographics of participants by recruiting both in-service and pre-service ESL teachers. While the COCA website itself as a tool could facilitate one’s language learning enormously, a number of other sociocultural and sociopolitical issues could limit its effectiveness, including access to technology, curriculum design, and students’ family background, thus research from different contexts is encouraged to enrich our understanding of the relationship between teachers’ perception of using computer corpora and English language teaching.
References
Home | Copyright © 2026, Russian-American Education Forum
